
Big data is a massive amount of information that is too large and complex for traditional data-processing application software to handle. Think of it as a constantly flowing firehose of data, and you need special tools to manage and understand it.
Big data definition in simple words
Big data encompasses structured, unstructured, and semi-structured data that grows exponentially over time. It can be analyzed to uncover valuable insights and inform strategic decision-making.
The term often describes data sets characterized by the “three Vs”: Volume (large amounts of data), Velocity (rapidly generated data), and Variety (diverse data types).
How does big data work?
Big data is processed through a series of stages.
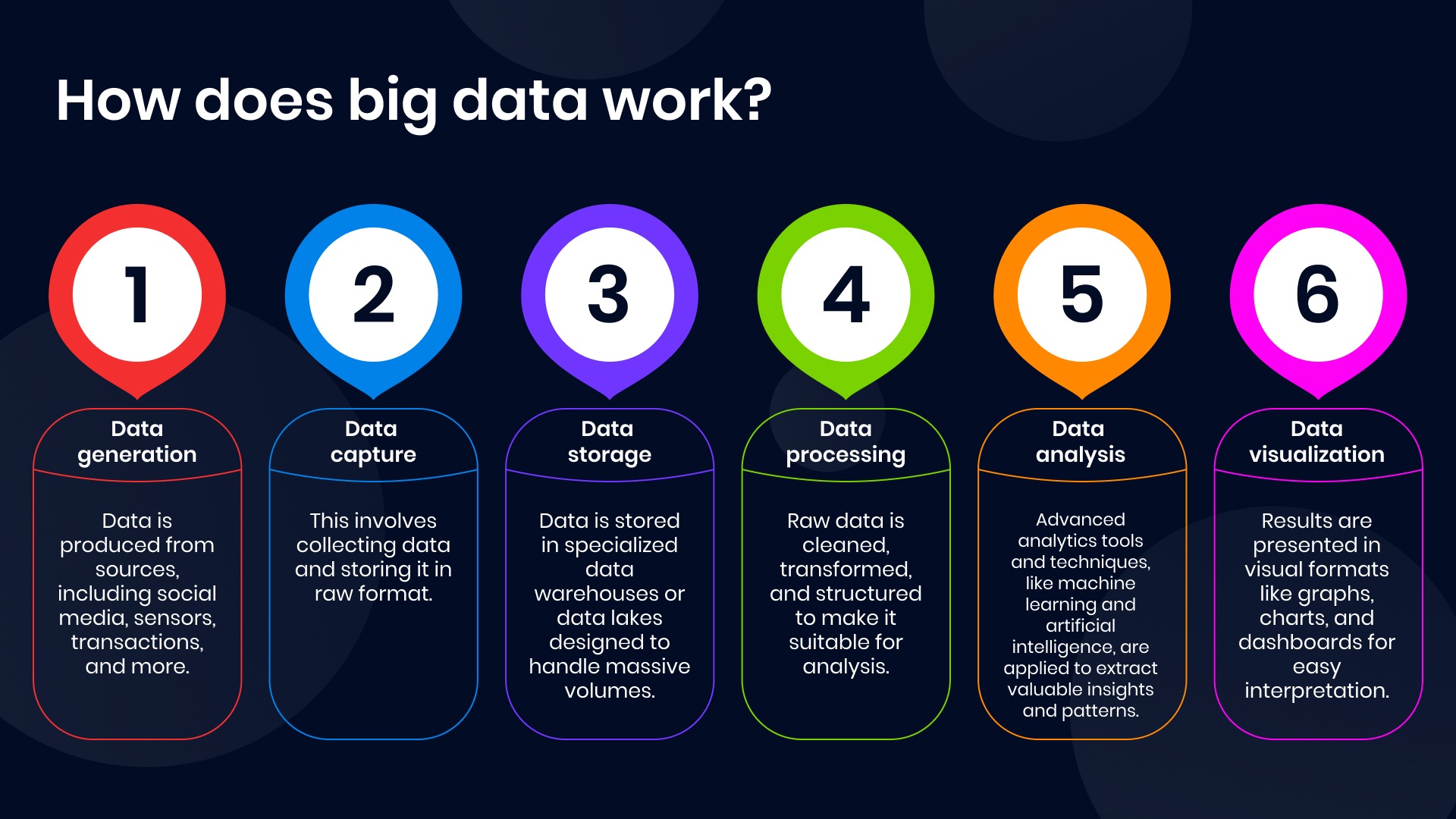
- Data generation → Data is produced from sources, including social media, sensors, transactions, and more.
- Data capture → This involves collecting data and storing it in raw format.
- Data storage → Data is stored in specialized data warehouses or data lakes designed to handle massive volumes.
- Data processing → Raw data is cleaned, transformed, and structured to make it suitable for analysis.
- Data analysis → Advanced analytics tools and techniques, like machine learning and artificial intelligence, are applied to extract valuable insights and patterns.
- Data visualization → Results are presented in visual formats like graphs, charts, and dashboards for easy interpretation.
What are the key technologies used in big data processing?
Big data processing relies on a combination of software and hardware technologies. Here are some of the most prominent ones.
Data storage
Hadoop Distributed File System (HDFS). Stores massive amounts of data across multiple nodes in a distributed cluster.
NoSQL databases. Designed for handling unstructured and semi-structured data, offering flexibility and scalability.
Data processing
Apache Hadoop. A framework for processing large datasets across clusters of computers using parallel processing.
Apache Spark. A fast and general-purpose cluster computing framework for big data processing.
MapReduce. A programming model for processing large data sets with parallel and distributed algorithms.
Data analysis
SQL and NoSQL databases. For structured and unstructured data querying and analysis.
Data mining tools. For discovering patterns and relationships within large data sets.
Machine learning and AI. For building predictive models and making data-driven decisions.
Business intelligence tools. For data visualization and reporting.
What is the practical use of big data?
Big data has revolutionized the way businesses operate and make decisions. In business, it helps with customer analytics, marketing optimization, fraud detection, supply chain management, and risk management. But that’s not all!
Big data in healthcare
Analyzing data helps identify potential disease outbreaks and develop prevention strategies. It became an important tool for virologists and immunologists, who use data to predict not only when and what kind of disease can outbreak, but also the exact stamm of a virus or an infection.
Big data helps create personalized medicine by tailoring treatments based on individual patient data. It also accelerates the drug development process by analyzing vast amounts of biomedical data.

Big data for the government
Big data can help create smart cities by optimizing urban planning, traffic management, and resource allocation. It can help the police to analyze crime patterns and improve policing strategies and response times. For disaster-prone regions, big data can help predict and respond to natural disasters.
Essentially, big data has the potential to transform any industry by providing insights that drive innovation, efficiency, and decision-making. That includes
- finance (fraud detection, risk assessment, algorithmic trading),
- manufacturing (predictive maintenance, quality control, supply chain optimization),
- energy (smart grids, energy efficiency, demand forecasting), and even
- agriculture (precision agriculture, crop yield prediction, and resource optimization).
What kinds of specialists work with big data?
The world of big data requires a diverse range of professionals to manage and extract value from complex datasets. Among the core roles are Data Engineers, Data Scientists, and Data Analysts. While these roles often intersect and collaborate, they have distinct responsibilities within big data.
Data engineers focus on building and maintaining the infrastructure that supports data processing and analysis. Their responsibilities include:
- Designing and constructing data pipelines.
- Developing and maintaining data warehouses and data lakes.
- Ensuring data quality and consistency.
- Optimizing data processing for performance and efficiency.
They usually need strong programming skills (Python, Java, Scala) and be able to work with database management, cloud computing (AWS, GCP, Azure), data warehousing, and big data tools (Hadoop, Spark).
A data analyst’s focus is on extracting insights from data to inform business decisions. Here’s exactly what they’re responsible for:
- Collecting, cleaning, and preparing data for analysis.
- Performing statistical analysis and data mining.
- Creating visualizations and reports to communicate findings.
- Collaborating with stakeholders to understand business needs.
Data analysts should be pros in SQL, data visualization tools (Tableau, Power BI), and statistical software (R, Python).
Data scientists apply advanced statistical and machine-learning techniques to solve complex business problems. They do so by:
- Building predictive models and algorithms.
- Developing machine learning pipelines.
- Experimenting with new data sources and techniques.
- Communicating findings to technical and non-technical audiences.
Data scientists need strong programming skills (Python, R), knowledge of statistics, machine learning, and data mining, and a deep understanding of business problems.
In essence, Data Engineers build the foundation for data analysis by creating and maintaining the data infrastructure. Data Analysts focus on exploring and understanding data to uncover insights, while Data Scientists build predictive models and algorithms to solve complex business problems. These roles often work collaboratively to extract maximum value from data.

Along with this trio, there are also other supporting roles. A Data Architect will design the overall architecture for big data solutions. A Database Administrator will manage and maintain databases. A Data Warehouse Architect will design and implement data warehouses. A Business Analyst will translate business needs into data requirements. These roles often overlap and require a combination of technical and business skills. As the field evolves, new roles and specializations are also emerging.
What is the future of big data?
The future of big data is marked by exponential growth and increasing sophistication. These are just some of the trends we should expect in 2024 and beyond.
- Quantum computing promises to revolutionize big data processing by handling complex calculations at unprecedented speeds.
- Processing data closer to its source will reduce latency and improve real-time insights.
- AI and ML will become even more integrated into big data platforms, enabling more complex analysis and automation.
- As data becomes more valuable, regulations like GDPR and CCPA will continue to shape how data is collected, stored, and used.
- Responsible data practices, including bias detection and mitigation, will be crucial.
- Turning data into revenue streams will become increasingly important.
- The demand for skilled data scientists and analysts will continue to outpace supply.
Meanwhile, big data is not without its challenges. Ensuring its accuracy and consistency will remain a challenge and an opportunity for competitive advantage.

« Back to Glossary Index