
What does modern cloud app development really look like in 2025, and how do you get it right on AWS? Many teams ask: “What is correct modern cloud app development AWS?” The short answer from MWDN experts is that it’s no longer just about spinning up servers or running apps in Kubernetes. It’s about building fast, secure, and scalable systems using GitOps, automated delivery, built-in observability, and secure supply chains as your foundation.

In this guide, we’ll walk through the key principles that define modern cloud development today. Whether you’re on AWS or any other cloud, these patterns apply, and we’ll show how AWS services align with them.
Content:
- What modern cloud app development includes
- How it differs from “before”
- 2025: What’s new or newly practical
- A pragmatic 90-day starter plan
- How MWDN can help you build and scale cloud applications
What modern cloud app development includes
Modern cloud development is no longer about running apps on Kubernetes or moving fast with CI/CD. Today, cloud-native teams take a product mindset to the entire stack: platform, delivery, security, data, and cost. Their goal is to ship without compromising reliability or control.
That’s why many roadmaps now focus on what is correct modern cloud app development agile: a way of working where strong defaults, automated guardrails, and outcome-based metrics (like SLOs and unit economics) replace manual processes and vanity KPIs. Here’s what that looks like in practice.
Choosing the right foundation for cloud development
Most modern teams rely on containers and Kubernetes for always-on services, and use serverless for tasks that are event-driven or run in bursts. But picking tools isn’t enough; you need to think of your platform as a product.
That means publishing clear service templates, setting version and deprecation policies, and making the secure and scalable path the default for every team. All infrastructure should be defined as code and managed through Git-based pipelines. This ensures every change is reviewed, tested, and rolled back consistently.
If you’re building your architecture, treat your tech stack as what is correct modern cloud app development framework: something reusable, versioned, and continuously improved. Think of template versions and baseline images the same way you’d treat product versions. What you’re really creating is a platform that gives developers reliable, paved paths instead of custom-built environments.
Modern architectures also assume failure and change. That means event-driven designs to decouple services, contracts at the API and schema layer to enable independent deployability, and readiness for multi-region environments where RTO/RPO or data residency require it. Platform teams use policy-as-code to keep runtime variability under control and reserve “exceptions” for rare, audited cases.
Data and AI
Managed databases, data streams, and warehouses take care of scalability and availability, but what really matters is how well they’re managed. That’s where you will need governance: setting clear rules about who owns the data, how schemas evolve over time, and what counts as the official “source of truth” versus temporary or derived copies.
Instead of relying on fragile, scheduled batch jobs, teams now use Change Data Capture and real-time streaming pipelines. These tools automatically sync changes across caches, search indexes, analytics systems, and user-facing features.
If you’re mapping how to build a saas application, anchor early decisions in tenancy model, data contracts, and migration strategy. A lightweight saas development framework, plus saas application development best practices (versioned APIs, usage-based limits, tenant isolation tests, and cost-per-tenant telemetry) will keep growth from outpacing reliability.
AI services now sit on the same backbone as app services. The practical questions are capacity and safety: plan GPU utilization, choose where to serve models, and implement evaluation/guardrails for quality and compliance. Vector databases and feature stores help, but only when paired with lifecycle rules versioning, drift monitoring, and reproducible training data.
Observability and reliability
OpenTelemetry provides a unified instrumentation model for traces, metrics, and logs. However, the real advantage lies in its intent: defining SLOs that directly impact user experience, and then leveraging these to guide release velocity through error budgets. Sampling strategies and retention policies keep telemetry costs predictable while preserving debuggability.
A common question is “what is correct modern cloud app development or DevOps?” In practice, modern cloud development uses DevOps as the delivery discipline inside a broader platform approach: product teams own outcomes, pipelines enforce policy, and SLOs guard reliability.
Reliability is engineered, not inspected. Progressive delivery with automatic rollback shortens time-to-mitigation; chaos and load tests expose systemic bottlenecks before customers do. Teams couple RED/USE dashboards with business KPIs so they see both product and platform health at a glance.
Security and compliance
Supply-chain security is part of CI/CD rather than a separate audit ritual. Build systems produce signed artifacts and SBOMs; policies enforce provenance before deployment. At runtime, identity-aware access (workload identity, short-lived credentials) replaces long-lived secrets and network, and data policies enforce least privilege by default.
Compliance becomes “continuous” through automation: policy checks on pull requests, drift detection in environments, and tamper-evident logs. For sensitive workloads or partner data, confidential computing and customer-managed keys add isolation without rewriting the app. The outcome is auditable, repeatable security that scales with your release cadence.
Cost and sustainability
FinOps connects engineering choices to financial outcomes. Teams tag resources consistently, normalize cost data, and track unit metrics like cost per request, per active user, or per inference. Those metrics inform design: right-sizing and autoscaling to the diurnal curve, shifting to ARM/spot where safe, and using storage and caching tiers deliberately.
AI makes the cost conversation sharper. GPU minutes are expensive; utilization, batch windows, quantization, and caching can move the needle more than instance type alone. Sustainability is no longer abstract: carbon-aware scheduling, power-efficient instance families, and efficient code paths often save both emissions and money.
How it differs from “before”
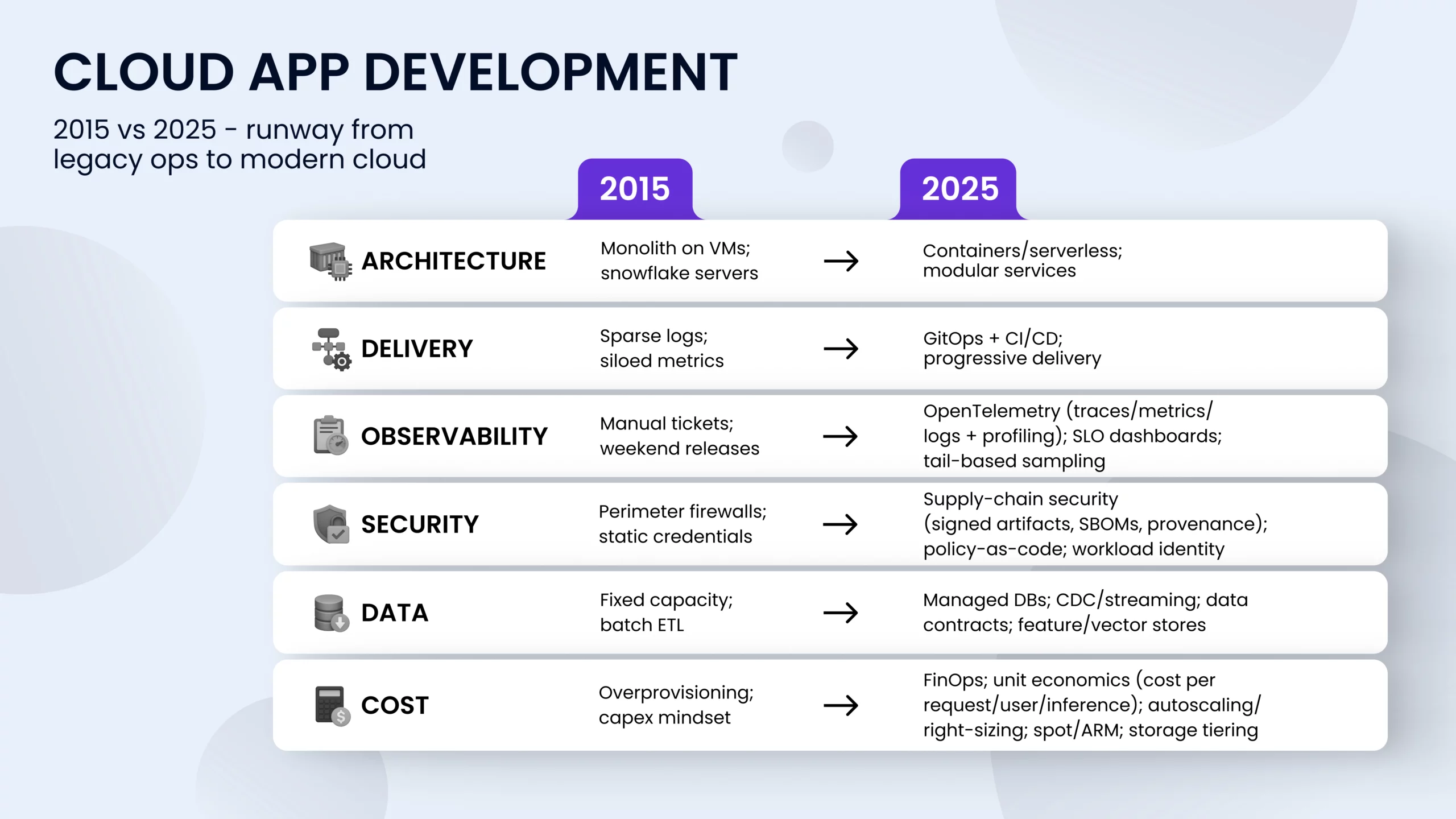
Earlier cloud eras optimized individual servers and change tickets; the 2025 approach optimizes flow. The center of gravity has shifted from “operate boxes” to “operate products,” where platform teams provide paved paths, guardrails, and shared services. Governance moved from weekly CAB meetings to policy in code, enforced automatically in CI/CD and at the runtime boundary.
Release mechanics changed, too. Instead of long-lived, hand-configured environments, teams use ephemeral preview stacks, reproducible by pipeline, and promote artifacts along identical stages. Incidents are treated as learning loops SLOs and error budgets regulate pace, and post-incident reviews feed changes into templates and policies so the whole system gets safer over time.
Architecturally, “microservices everywhere” gave way to modularity on a spectrum: modular monoliths for simpler domains, services where independent scaling or ownership justifies the split.
2025: What’s new or newly practical
In 2025, four building blocks crossed the chasm from promising to practical: standardized traffic management in Kubernetes, lightweight meshes, unified telemetry, and AI as a first-class workload. Together, they cut operational drag and clarify team boundaries. Here’s how these shifts show up in day-to-day engineering.
1) Kubernetes networking grows up
Gateway API doesn’t just replace quirky Ingress objects; it separates concerns. Platform teams manage the GatewayClass and Gateways (the “roads”), while app teams own HTTPRoute/GRPCRoute (the “traffic”). Cross-namespace delegation and ReferenceGrant enable safe multi-tenant setups, and policy CRDs apply consistent auth, TLS, and rate limits across clusters and clouds. The result is predictable routing, simpler ownership boundaries, and fewer bespoke controllers.
2) Mesh, without the baggage
Sidecar-less meshes lower cost and failure surface by moving from “one proxy per pod” to shared dataplanes. Teams can start at L4 mTLS only for identity and encryption, then layer in L7 features: traffic shaping, retries, timeouts, only where the ROI is clear. This staged adoption model addresses the two primary historical concerns about meshes: operational heft and the “all-or-nothing” rollout issue. In practice, you keep Gateway/API ingress simple, use ambient mesh for service-to-service security and policy, and avoid sprinkling sidecars everywhere.
3) OpenTelemetry everywhere
OTel’s value in 2025 is less about checklists and more about control. Unified semantic conventions let you connect user journeys to system bottlenecks; exemplars link metrics to traces for “click-through debugging”; and tail-based sampling captures the outliers that actually matter while keeping storage sane. Centralized collectors standardize enrichment and route data to multiple backends without vendor glue code.
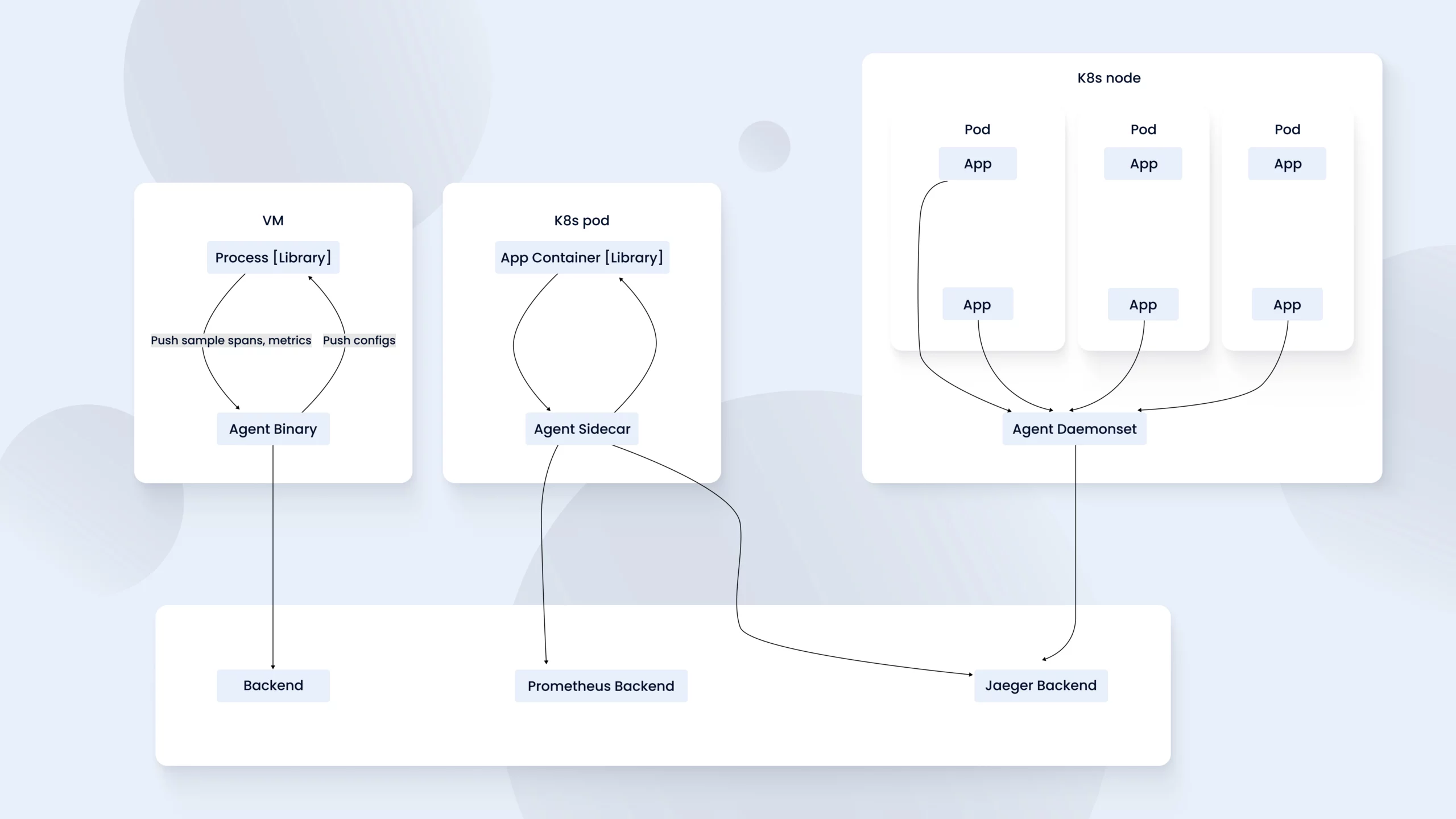
Running OpenTelemetry Collector as an agent
4) AI-native operations
Running AI alongside app services is now a platform problem, not a one-off project. Capacity planning means bin-packing GPUs, mixing spot and on-demand, and using quantization or low-rank adapters to squeeze more throughput per dollar. Inference is productized: tiered endpoints, guardrails for PII/toxicity, offline eval sets to gate model releases, and shadow traffic to compare candidates before switching. Data gravity is managed with CDC into feature stores and vector indexes, plus prompt/embedding caches to cut token and latency costs. The guiding principle: treat models like services with versions, SLOs, and release policies because that’s what they are now.
A pragmatic 90-day starter plan
The aim isn’t to “adopt tools,” it’s to prove a safer, faster, cheaper way of working and then make it the default. Over 90 days, you’ll stand up a paved path, harden the supply chain, and wire observability to business outcomes on one or two real services so the organization can copy success rather than debate theory.
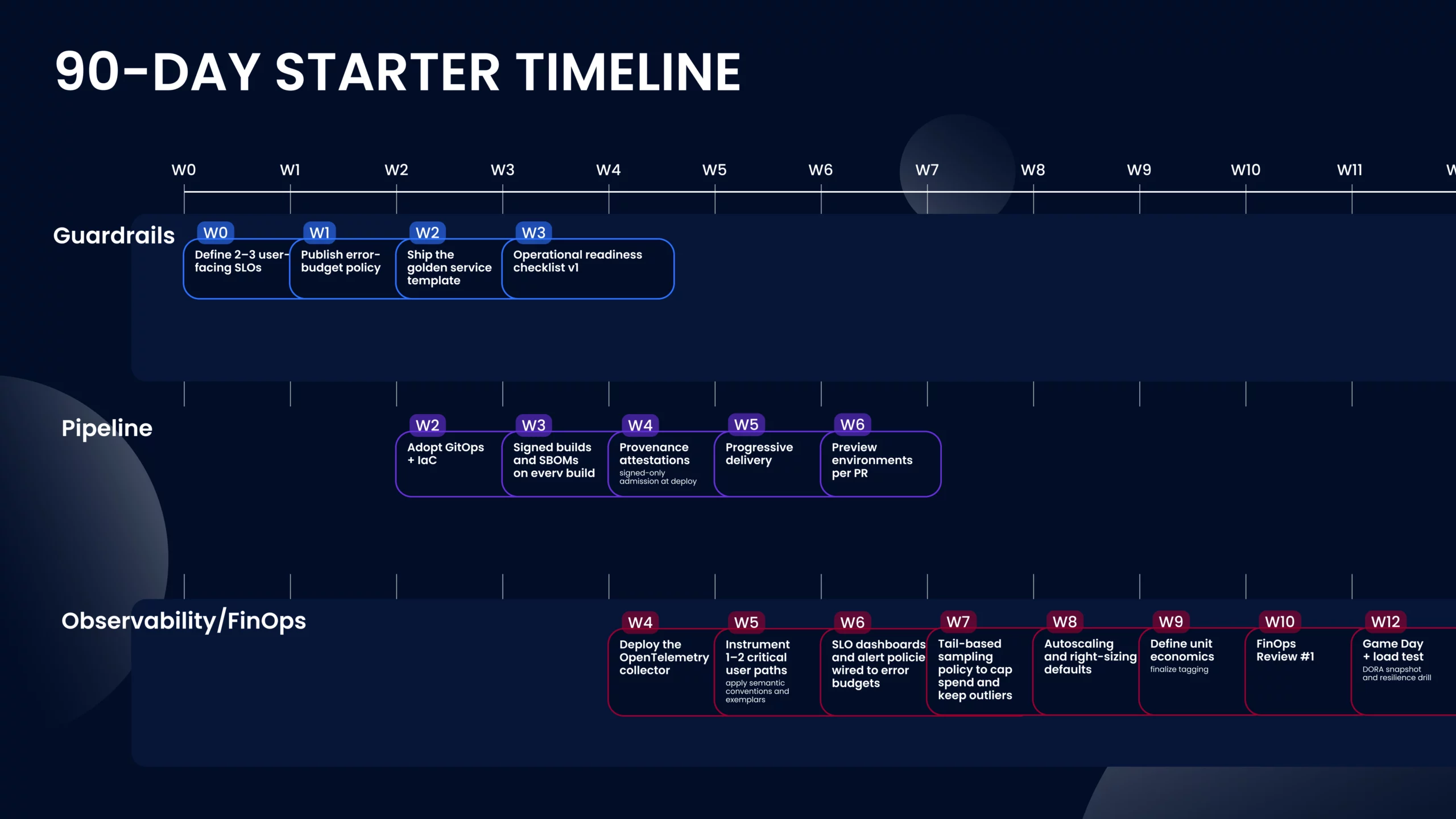
1) Set guardrails (weeks 0–3)
Pick two or three user-facing SLOs and write an error-budget policy that governs release pace and rollback. Define a single golden service template that every new service must use: scaffolded repo, base container image, health endpoints, OpenTelemetry SDK, default K8s resources with requests/limits, NetworkPolicy, PodSecurity levels, and mandatory cost/tag annotations.
Decide environment names and promotion flow (preview → staging → prod) and codify promotion gates (tests passed, security checks green, error budget healthy). Close with an Operational Readiness Checklist v1 (runbook link, on-call rotation, SLO dashboard URL, pager policy). The insight: guardrails remove negotiation from every delivery; they make the secure, observable path the easy path.
2) Harden the pipeline (weeks 2–6)
Move changes through GitOps and IaC so infra, policies, and apps travel together. Produce signed artifacts and SBOMs in CI; verify them at deploy time with policy-as-code. Add provenance attestations and image scanning; enforce branch protection, required reviews, and short-lived workload identities instead of static secrets. Enable progressive delivery with automatic rollback tied to SLO/error signals, not just HTTP 5xx. Standardize preview environments for every PR to reduce integration surprises. Make the build reproducible, so you can answer “what’s running and why?” in minutes.
3) Instrument and optimize (weeks 4–12)
Roll out OpenTelemetry collectors and a minimal semantic convention so traces, metrics, and logs line up with user journeys. Use tail-based sampling and exemplars (metrics ↔ traces) to keep costs sane while preserving debuggability on the 1% of traffic that hurts.
Establish autoscaling defaults and right-sizing policies; for AI/inference paths, track GPU utilization, cache hit rates, and token/minute spend. Start a monthly FinOps review anchored on unit metrics and log the design decisions those numbers drive.
By Day 90, “what good looks like”: one production service running on the golden path; SLOs and error budgets enforced by the pipeline; signed, attestable releases; OTel data powering both debugging and release gates; autoscaling and right-sizing saving money you can quantify; and a rinse-and-repeat template other teams can adopt without hand-holding.
How MWDN can help you build and scale cloud applications
Behind every modern cloud app is a team of engineers who understand the complexity under the hood: containers, serverless runtimes, declarative infrastructure, multi-region networking, AI workloads, observability, FinOps, and compliance frameworks like SLSA or SSDF. You need people who’ve actually shipped scalable systems, managed reliability under pressure, and know where to apply the new tools and where to keep things simple.
We provide cloud engineers, DevOps specialists, and platform developers who already know what “good” looks like and how to build toward it pragmatically. Our engineers are fluent in the modern stack: Kubernetes, Terraform, GitOps, OpenTelemetry, service meshes, model-serving pipelines, and cloud-native security, all while working across AWS, GCP, Azure, or hybrid environments.
If you’re planning to launch or scale a cloud application, and you need experts who understand the new realities, not just how to operate infrastructure, but how to shape it into a product that moves fast, stays reliable, and doesn’t burn through your budget, MWDN is ready to partner with you.